TensorFlow - 梯度下降优化
梯度下降优化被认为是数据科学中的一个重要概念。
考虑下面显示的步骤来理解梯度下降优化的实现 −
步骤 1
包括必要的模块和 x 和 y 变量的声明,我们将通过它们来定义梯度下降优化。
import tensorflow as tf x = tf.Variable(2, name = 'x', dtype = tf.float32) log_x = tf.log(x) log_x_squared = tf.square(log_x) optimizer = tf.train.GradientDescentOptimizer(0.5) train = optimizer.minimize(log_x_squared)
步骤 2
初始化必要的变量并调用优化器来定义和调用相应的函数。
init = tf.initialize_all_variables()
def optimize():
with tf.Session() as session:
session.run(init)
print("starting at", "x:", session.run(x), "log(x)^2:", session.run(log_x_squared))
for step in range(10):
session.run(train)
print("step", step, "x:", session.run(x), "log(x)^2:", session.run(log_x_squared))
optimize()
上面的代码行生成一个输出,如下面的屏幕截图所示 −
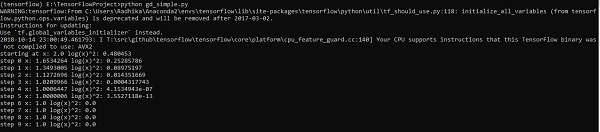
我们可以看到,必要的时期和迭代计算如输出所示。

